Architecture
참고 : https://dataflow.spring.io/docs/concepts/architecture/ (opens in a new tab)
서버 Component 들
참고 : https://dataflow.spring.io/docs/concepts/architecture/#server-components (opens in a new tab)
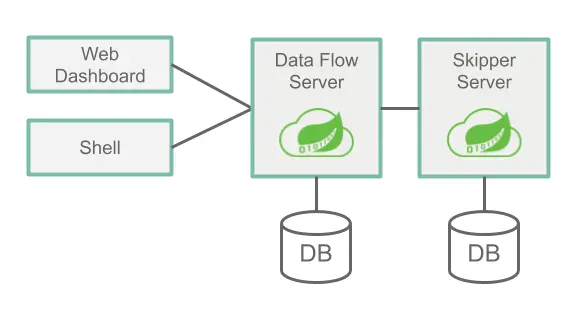
서버 컴포넌트는 Data Flow Server, Skipper Server 이렇게 크게 두개의 컴포넌트로 나뉘어 집니다. 그리고 Web Dashboard, Shell 을 통해서 Data Flow Server 내에서 데이터가 처리되는 현황을 볼수 있고, 데이터의 흐름을 생성하는 것 역시 가능합니다.
Data Flow Server 는 주로 데이터를 처리하고 관리하고 스트림 처리, 배치 작업의 케쥴링 하는 것과 같은 실제 데이터의 관리 제어 기능들을 수행합니다.
Skipper Server 는 주로 Stream 을 Data Flow Server 로의 배포를 담당하며, 각 Stream 에 대한 메타 정보들을 관리합니다. 배포는 블루/그린 방식으로 이뤄지며, 업그레드, 롤백, 배포 기록, Stream 에 대한 명세를 의미하는 매니페스트 파일의 history 를 저장하는 역할을 수행합니다.
Data Flow Server
참고 : https://dataflow.spring.io/docs/concepts/architecture/#data-flow-server (opens in a new tab)
Data Flow Server 는 주로 아래와 같은 일들을 합니다.
- Parsing : DSL(Domain-Specific Language)을 기반의 스트림 및 Batch 작업 정의를 파싱합니다.
- Validating & Persisting : Stream, Task, 배치 잡 정의 들을 Validating 하거나 Persisting 합니다.
- artifact 등록 : jar, Docker Image 같은 artifact 들을 DSL 에 사용되는 이름으로 등록합니다.
- Batch Job 배포 : batch job 들을 하나 또는 하나 이상의 플랫폼에 배포합니다.
- Job 스케쥴링 : Job 의 스케쥴링을 플랫폼에 위임합니다.
- Query : Detailed Task, Batch Job 실행 history 데이터를 Query 합니다.
- 메시징 입출력 설정,배포 Properties 관리 : 메시징 입력 및 출력을 구성하는 스트림에 Configuration Properties 를 추가하고 배포 Properties (예: 초기 인스턴스 수, 메모리 요구 사항 및 데이터 분할)를 전달합니다.
- Skipper 에게 Stream 을 배포하도록 위임 : 스트림 배포를 Skipper에 위임(Delegating)합니다.
- 작업 Auditing : Stream 생성, Deployment, 배포 취소, Batch 생성, Batch Launching, Batch 등의 작업들을 Auditing 합니다.
- Tab-완성 기능 : Stream, Batch Job 에 대해 Tab-완성 기능을 제공합니다.
Skipper Server
참고 : https://dataflow.spring.io/docs/concepts/architecture/#skipper-server (opens in a new tab)
Skipper Server 를 사용하면 아래의 작업들이 가능합니다.
- 배포 : 하나 이상의 플랫폼 들에 Stream (스트림) 을 배포합니다.
- 업그레이드, 롤백 : 하나 이상의 플랫폼 들에 대해 Stream 을 Upgrade 하거나 Rollback 합니다.
- 기록 저장 : 각 Stream 의 매니페스트 파일 기록을 저장합니다.
Database
참고 : https://dataflow.spring.io/docs/concepts/architecture/#database (opens in a new tab)
Data Flow Server와 Skipper Server에는 RDBMS가 설치되어 있어야 합니다. 기본적으로 서버는 내장된 H2 데이터베이스를 사용합니다. 외부 데이터베이스를 사용하도록 서버를 구성할 수 있습니다. 지원되는 데이터베이스는 H2, HSQLDB, MariaDB, Oracle, Postgresql, DB2 및 SqlServer입니다. 스키마는 각 서버가 시작될 때 자동으로 생성됩니다. 더 자세한 내용은 Security Section (opens in a new tab) 에 설명되어 있습니다.
Security
Data Flow, Skipper Server 는 REST 엔드포인트를 보호(secure)하기 위해 OAuth2.0 인증을 사용합니다. OAuth 2.0 인증을 위해 Basic Authentication 또는 OAuth2 Access Token 을 통해서 접근이 가능합니다.
애플리케이션 유형
참고 : https://dataflow.spring.io/docs/concepts/architecture/#application-types (opens in a new tab)
Spring Cloud Data Flow 에서는 애플리케이션의 유형을 두가지로 분류하고, 두 가지 유형에 따라 다르게 운영이 가능해집니다.
- 장기 애플리케이션(수명이 긴 애플리케이션) : 무한에 까까운 데이터의 처리
- 1) 무한에 가까운 데이터가 소비되거나 생성되는 메시지 기반 애플리케이션
- 2) 입력, 출력을 가지는 메시지 기반 애플리케이션. 메시징 미들웨어를 사용하지 않는 애플리케이션일 경우도 있다.
- 단기 애플리케이션(수명이 짧은 애플리케이션) : 유한한 데이터를 처리한 후 종료되는 애플리케이션
- 1) 코드 실행 + Data Flow 데이터베이스에 실행 상태 기록하는 작업
- Spring Cloud Task 프레임워크를 선별적으로 사용 가능.
- 꼭 Java 애플리케이션일 필요는 없습니다.
- 애플리케이션은 Data Flow 의 데이터베이스에 실행 상태를 기록해야 합니다.
- 2)
1)의 작업을 배치 프로세싱을 지원하는 스프링 배치 프레임워크를 이용해서 수행하는 애플리케이션
- 1) 코드 실행 + Data Flow 데이터베이스에 실행 상태 기록하는 작업
장기 애플리케이션은 Spring Cloud Stream 프레임워크 기반으로 작성하고, 단기 애플리케이션은 Spring Cloud Task 프레임워크, Spring Batch 프레임워크를 기반으로 작성하는 것이 일반적인 관례입니다. Spring 을 사용하지 않는 장기 애플리케이션, 단기 애플리케이션을 작성하는 것 역시 가능합니다. 그리고 다른 언어로도 작성 가능합니다.
런타임 환경에 따라 아래의 두 가지 방식으로 애플리케이션의 패키징이 가능합니다.
- jar 파일 방식 : Spring Boot Uber Jar 라이브러리를 mvnrepository 또는 Nexus 등을 이용해서 다운로드 및 관리
- Docker 방식 : Docker 레지스트리를 통해서 이미지를 받아오고 jib, plantir, dockerfile, 등을 이용해서 패키징
장기 애플리케이션 (Long-lived Applications)
참고 : https://dataflow.spring.io/docs/concepts/architecture/#long-lived-applications (opens in a new tab)
- 소스, 프로세서 및 싱크가 있는 스트림
- 다중 입력 및 출력이 있는 스트림
소스, 프로세서 및 싱크가 있는 스트림
Spring Cloud Stream 은 아래와 같은 일반적인 메시지 교환 계약 (Exchange Contracts)를 따르는 바인딩 인터페이스를 제공합니다.
Source: 메시지를 대상으로 보내는 메시지 생성자입니다.Sink: 대상에서 메시지를 읽는 메시지 소비자입니다.Processor: 소스와 싱크의 조합입니다. 프로세서는 대상의 메시지를 소비하고 다른 대상으로 보낼 메시지를 생성합니다.
아래 예제는 쉘을 사용할 경우 수행 가능한 예제입니다.
dataflow:>app register --name http --type source --uri maven://org.springframework.cloud.stream.app:http-source-rabbit:3.2.1
Successfully registered application 'source:http'
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:3.2.1
Successfully registered application 'sink:log'위의 예제는 소스 http, 싱크 log 를 등록하는 쉘 스크립트입니다.
Data Flow 에 등록된 http, log 를 사용하면, 아래 예제 처럼 pipe, filter 구문을 사용하는 Stream Pipeline DSL 을 이용해서 스트림 정의(Stream Definition)을 생성하는 것이 가능합니다.
다중 입력 및 출력이 있는 스트림
아래 내용은 의역을 했습니다. 직역을 할 경우 내용이 모호해지는 경향이 있기 때문에 의역을 통해서 요약을 했습니다. 다소 주관적인 입장으로 요약을 했기에 많은 원본 글 내용을 줄였습니다.
Source, Sink, Processor 인터페이스의 정의를 살펴보면 단일 입력, 단일 출력을 가지고 있습니다.
application properties 등에 정의된 속성들을 이용해서 입력,출력을 정의해두면 Source, Sink, Processor 와 같은 인터페이스의 정의를 이용해서 Data Flow 가 각각의 입력 대상과 출력 대상을 연결해줄 수 있게 됩니다.
그런데 Source, Sink, Processor 는 단일 입력, 단일 출력입니다. 둘 이상의 입력, 출력 대상에 대해서는 바인딩이 불가능합니다. 일반적으로 메시지 처리를 하는 애플리케이션은 둘 이상의 입력 또는 출력대상이 존재하는 경우가 많습니다.
Spring Cloud Stream 은 이런 경우에 대해 커스텀한 Binding 인터페이스를 사용자 정의로 직접 만들어서 사용할 수 있도록 지원합니다. 따라서 둘 이상의 입력, 출력이 있을 경우 Source, Sink, Processor 대신 커스텀한 Binding 인터페이스를 직접 정의해서 사용하는 것 역시 가능합니다.
만약 다중 입력 애플리케이션을 스트림에 포함하려 할 경우 반드시 source, sink, or processor type 대신 애플리케이션을 app 타입을 이용해서 등록해야 합니다. Stream 정의는 Stream Application DSL 이라는 문법을 사용해서 정의하는데, 이것은 || 기호를 사용해서 정의합니다. Unix, Linux 등에서 쓰이는 일반적인 단일 파이프 기호는 | 인데, Stream Application DSL 에서는 | 을 두개 씀으로써 병렬 파이프라인 이라는 것을 강조하는 기호를 사용합니다.
아래는 그 예제입니다.
dataflow:> stream create --definition "orderGeneratorApp || baristaApp || hotDrinkDeliveryApp || coldDrinkDeliveryApp" --name orderStream|| 는 병렬을 의미하는 것으로 생각하시기 바랍니다. 이 것은 응용프로그램 간의 암시적인 연결 없이 병렬을 의미합니다.
Stream Application DSL 을 이용하해서 메시징 미들웨어를 사용하지 않으면서 단일 애플리케이션을 이용해서 Stream 을 생성하는 것 역시 가능합니다.
단기 애플리케이션 (Short-lived Applications)
참고 : https://dataflow.spring.io/docs/concepts/architecture/#short-lived-applications (opens in a new tab)
- Spring Cloud Task 애플리케이션
- Spring Batch 프레임워크
Spring Batch 프레임워크는 Sprng Cloud Task 보다 풍부한 기능 세트를 제공하며, 대용량 데이터를 처라할 때 권장됩니다.
Spring Cloud Task 는 Spring Batch 와 통합되어 Spring Cloud Task 애플리케이션이 Spring Batch 작업을 정의한 경우 Spring Cloud Task 와 Spring Batch 실행 테이블 간의 링크가 생성됩니다.
Composed Task
참고 : https://dataflow.spring.io/docs/concepts/architecture/#composed-tasks (opens in a new tab)
Composed Task DSL 을 이용해서 Composed Task 를 정의하는 것이 가능합니다. Composed Task DSL 에는 몇몇 기호가 있습니다. 여기에 대해서는 reference (opens in a new tab) 에 자세히 설명되어 있습니다. 아래는 몇몇 기호중 한가지 예입니다.
dataflow:> task create simpleComposedTask --definition "task1 && task2"위의 DSL 표현식( task1 && task2) 은 task2 까지 모두 성공적으로 실행되어야 시작됨을 의미합니다. task1 작업 그래프는 Composed Task Runner 라는 작업 애플리케이션을 통해서 실행됩니다.
애플리케이션 메타 데이터
참고 : https://dataflow.spring.io/docs/concepts/architecture/#prebuilt-applications (opens in a new tab)
장기(Long Lived), 단기(Short Lived) 애플리케이션 들은 모두 메타데이터를 제공 가능합니다. 메타 데이터는 Configuration Properties (설정 속성)를 통해 제공되는데, 속성 값들을 Configuration 으로 정의하는 것을 의미합니다.
이 메타데이터를 통해 Shell, UI Tool 을 통해서 데이터 파이프라인을 구성할 때 코드완성 기능 등을 제공가능해지게 됩니다. 메타데이터를 생성하고, 사용하는 방법에 대해서는 detailed guide (opens in a new tab) 에서 자세히 설명하고 있습니다.
Prebuilt Applications
참고 : https://dataflow.spring.io/docs/concepts/architecture/#prebuilt-applications (opens in a new tab)
개발 작업 시작 시에 미리 빌드 된 애플리케이션 (Prebuilt Applications)을 활용해서 공통 데이터 소스와 싱크를 통합가능합니다. 예를 들면 Cassandra 에 데이터를 쓰는 cassandra 싱크와 유입데이터를 변환(transform) 하는 작업을 Groovy Script 를 이용해 수행하는 groovy-transform 프로세서를 사용하는 예를 들 수 있습니다.
등록하는 방법들, 사용법 등 Prebuild Applications 에 대한 더 많은 정보는 여기 (opens in a new tab)를 참고하시면 됩니다.
마이크로서비스 아키텍처 스타일
참고 : https://dataflow.spring.io/docs/concepts/architecture/#streams (opens in a new tab)
Data Flow, Skipper 는 스트림, Composed Batch Job 을 마이크로 서비스 컬렉션으로 플랫폼에 배포가 가능합니다.
Skipper 를 사용하면 Runtime 환경에서 이렇게 배포된 각각의 마이크로 서비스 애플리케이션들을 독립적으로 롤백하거나 업그레이드하는 것이 가능해집니다.
Data Flow 서버를 사용하면, 필요한 입력, 출력항목, 파티션, 메트릭 기능을 통해 여러 애플리케이션을 런타임 환경에서 배포하는 작업을 단순화하는 데에 도움이 됩니다. 하지만 각각의 마이크로서비스 애플리케이션을 수동으로 배포하고 Data Flow 또는 Skipper 를 전혀 사용하지 않도록 선택하는 것 역시 가능합니다.
다른 아키텍처와의 비교
가이드 문서에서는 Apache Spark, Apache Flink, Google Cloud Data flow 등과 같은 스트림 및 Batch 처리 플랫폼과 다르다는 이야기를 합니다. Apache Spark, Apache Flink, Google Cloud Data Flow 와 같은 플랫폼들은 전용 컴퓨팅엔진에서 실행되며, Spring Cloud Data Flow 에 비해 조금 더 복잡한 연산을 수행하는데, SCDF 를 사용하면 이렇게 이종의 플랫폼들에서의 처리와 제어를 다른 플랫폼인 SCDF 로 위임할 수 있다는 점을 장점으로 이야기하고 있습니다.
뭔가 길게 설명하고 포장을 하고 있는데, 요약해보면, 여러가지의 데이터 플랫폼들을 하나의 SCDF 라는 플랫폼에서 모두 모아서 관리할 수 있다는 점을 장점으로 이야기하고 있습니다.
Streams
이번 챕터는 https://dataflow.spring.io/docs/concepts/architecture/#streams (opens in a new tab) 의 내용을 요약한 내용입니다. 원본 문서의 내용이 뭔가 졸면서 쓴듯한 두서없는 글이여서 어느 정도는 의역을 했습니다.
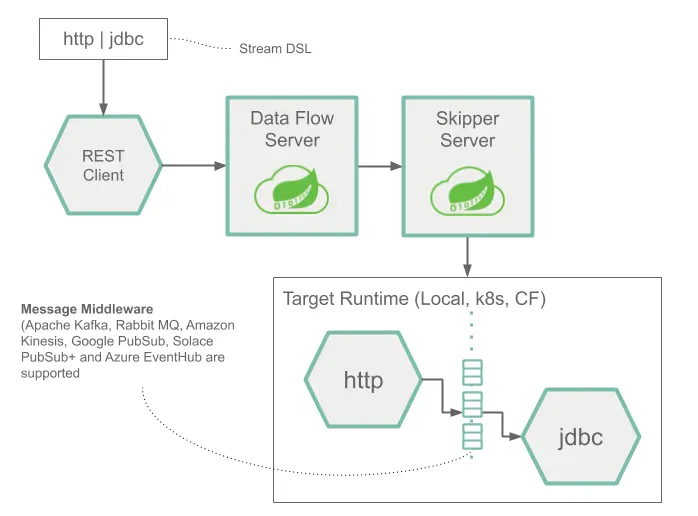
Stream DSL 로 작성된 프로그램의 특정 로직이 HTTP POST 요청을 통해 Data Flow Server 에 요청을 하고 있습니다. http source , jdbc sink 로 정의된 Stream 은 Skipper Server 에 의해 배포되어 있습니다. POST 요청을 통해 전달된 http 요청은 database 에 해당 데이터의 저장을 수행하게 됩니다.
아래는 Multiple Pipeline 스트림의 예시입니다.
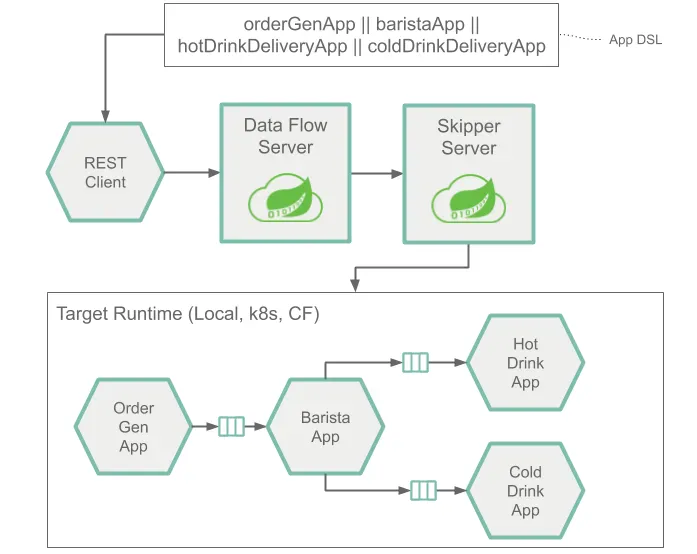
orderGenApp 의 결과가 baristaApp 의 입력으로 가며, baristaApp 의 출력은 hotDrinkDeliveryApp 의 입력으로 전달됩니다. 그리고 마지막으로 hotDrinkDeliveryApp 의 출력은 codDrinkDeliveryApp 의 입력으로 전달됩니다.
이렇게 정의된 Stream DSL 기반의 애플리케이션은 Skipper 에 의해 배포된 것이며, 이것의 상태를 조회하거나 제어하는 것은 Data Flow 서버를 통해서 가능합니다.
orderGenApp, baristaApp, hotDrinkDeliveryApp, coldDrinkDeliveryApp 각각은 병렬 처리가 적용된 마이크로 서비스 이며, 이것들을 파이프라이닝 하고 있는데, 이 파이프라인 내의 각각의 마이크로 서비스를 배포하는 역할은 Skipper 서버가 담당하고, 이 것의 흐름을 모니터링하거나 상태를 조회하거나 파이프라인을 연결하는 것은 Data Flow 서버를 통해 가능합니다.
이렇게 병렬처리가 가능한 파이프라인은 Spring Cloud Data Flow 에서는 || 기호로 표기합니다. 리눅스의 | 명령어(파이프라인 명령어)에서 병렬처리가 가능하다는 것을 강조하기 위해 | 을 하나 더 추가한 || 기호를 통해 병렬 파이프라인이라는 것을 강조하고 있습니다.
아래는 Task, Batch Job 의 예시입니다.

DataFlow 서버는 필요한 Timestamp 태스크를 Launch 하는 역할을 합니다. 그리고 Timestamp Task 는 Database 에 Task 의 상태(성공,실패, 오류, 실행시각 등)를 기록하게 됩니다.
아래는 Composed Task 의 예입니다.

myTask1 && myTask2 로 표기하는 Composed Task 는 위의 그림과 같이 myTask1 이 성공적으로 끝나야 그다음 작업인 myTask2 로 진행이 가능하며, myTask2 가 실패하면 myTask1 역시 실패로 기록되게 됩니다.
Platforms
참고 : https://dataflow.spring.io/docs/concepts/architecture/#streams (opens in a new tab)
Spring Cloud Data Flow 서버는 Cloud Foundry, Kubernetes, 로컬 머신 등에 배포 가능합니다. 공식 문서에서는 어떻게든 말을 더 쓰려고 길게 쓰려고 하는데, 이 내용이 전부입니다.